The Ultimate Governance Playbook for Enterprise LLM Fine-Tuning
Learn how enterprise LLM fine-tuning becomes safe, auditable, and compliant with a governance-first lifecycle for data, models, and approvals at scale.

Most teams still treat enterprise LLM fine-tuning as a modeling problem: collect some data, tweak some weights, ship the model. In regulated enterprises, that mindset is dangerously incomplete. Every fine-tuning run is a change to a semi-autonomous business process—and that makes it a governance problem first, and a modeling problem second.
If you can’t explain, reproduce, or defend what your fine-tuned LLM did last week to an auditor, a regulator, or a key customer, you don’t have an AI solution—you have a liability. SOC 2, GDPR, HIPAA, PCI, internal risk committees, and customer security reviews all converge on the same questions: who changed the model, based on what data, under whose approval, with what tests?
This playbook walks through a compliance-first lifecycle for responsible AI in large organizations: dataset lineage, validation suites, model versioning, evaluation criteria, and retraining cadence. We’ll translate abstract "model governance" into practical workflows, templates, and artifacts that legal, compliance, security, and ML teams can all live with.
At Buzzi.ai, we build AI agents and automation that bake governance and model ops into the way you do everyday LLM work—rather than bolting it on at the end. Think of this as a blueprint you can implement yourself, or accelerate with a partner who has already operationalized it across multiple regulated enterprises.
Enterprise LLM fine-tuning: from model tweak to governance risk
What makes enterprise LLM fine-tuning different
In general terms, fine-tuning an LLM means taking a base model and training it further on your own data so its behavior fits your domain, your tone, and your workflows. For a consumer app or early-stage startup, that might mean better answers to support questions or more relevant content suggestions. The risks are real, but the blast radius is usually limited and the governance bar is relatively low.
In regulated enterprises, everything changes. Once a fine-tuned LLM starts answering healthcare questions, drafting financial advice, or handling customer complaints, regulators treat it as part of a controlled business process. That means it inherits all the compliance requirements you already know well: SOC 2 controls, GDPR and other data protection laws, HIPAA in healthcare, PCI for payments, plus customer security questionnaires that read like mini-regulations.
Every tweak to model behavior is now a change to a semi-autonomous workflow: how your organization speaks, what it recommends, what it redacts, and what it escalates to humans. Those changes need to be governed, documented, and auditable just like changes to a core banking system or an EHR platform.
Put differently: enterprise LLM fine-tuning isn’t just “improve accuracy.” It is “safely update the behavior of a powerful, probabilistic policy engine that regulators can and will ask you about later.”
Compare a typical startup fine-tuning process with an enterprise one:
- Documentation: startups may keep a README; enterprises need formal requirements, risk assessments, and model cards.
- Approvals: startups ship when the PM is happy; enterprises require security, legal, and compliance sign-offs.
- SLAs and guarantees: startups promise “best effort”; enterprises must show repeatability, rollback options, and clear ownership.
Why fine-tuning introduces compliance and audit risk
Fine-tuning is uniquely risky because it modifies what the model knows and how it behaves in ways that are hard to reverse or inspect. If sensitive customer data sneaks into your training set, it can end up implicitly embedded in the model weights. That’s both a privacy risk and a nightmare for data-rights requests or lawful-basis reviews.
On top of that, ad hoc datasets and undocumented experiments break traceability. If different teams are fine-tuning their own copies of a model using slightly different scripts and random data scraps, there’s no clear line from a problematic output back to the data and code that produced it. This violates expectations in almost every responsible AI and risk management framework.
Imagine a hypothetical: a fine-tuned LLM used in a wealth-management chatbot suggests an inappropriate investment to a retail client. Months later, during an internal investigation triggered by a complaint, the team tries to answer basic audit questions: Which model version produced that response? What dataset was it trained on? Who approved that dataset? What evaluation tests did it pass?
Without structured audit logs and data provenance, the answers are guesses. Regulators are increasingly intolerant of "we don’t know" as an explanation. The more critical the domain—finance, healthcare, energy—the more your LLM program must be able to reconstruct decisions from output all the way back to data and approvals.
From accuracy-first to governance-first mindset
Most ML teams are wired to optimize for accuracy or user satisfaction scores. In the enterprise, that’s necessary but not sufficient. A model can be more accurate on benchmark questions and still systematically violate internal policy or regulatory expectations.
A true AI governance framework for LLMs treats governance as a first-class design constraint: models should only be as capable as we can control, explain, and monitor. That means building policy enforcement, traceability, and risk controls into every stage of the lifecycle—from requirements and dataset selection to deployment and runtime monitoring.
Conceptually, you can picture a lifecycle diagram that runs: requirements → data sourcing and lineage → experimentation → evaluation and validation → approval and promotion → monitoring and retraining. At each stage, there are explicit governance checkpoints: sign-offs, artifacts to publish, and policies to enforce. The rest of this guide unpacks how to implement that lifecycle in a way that your auditors—and your leadership—can trust.
Designing a compliance-first LLM fine-tuning lifecycle
Start from business, risk, and policy requirements
A good governance program starts long before anyone touches a GPU. For any enterprise LLM fine-tuning initiative, you need a clear statement of the business objective, the expected model behaviors, and the hard constraints driven by risk and policy. “Automate 30% of Tier-1 support tickets” is not enough; you need to spell out what the LLM may and may not do.
For example, a requirements document for a customer-support assistant might state that the model must: never disclose PII beyond what the user already provided, always include a disclaimer for billing advice, escalate to a human for specific high-risk topics, and follow defined tone guidelines. These behaviors tie directly back to internal policies on PII, GDPR data retention, customer communications, and complaint handling.
Those requirements should become the first artifact in your enterprise LLM fine-tuning governance framework. Treat them like a product spec merged with a policy checklist. If your auditors or customers later ask why the model behaves a certain way, you can point to a signed-off document that connects business goals to compliance requirements.

A concrete excerpt from such a requirements doc might read:
For any response containing account balances or payment schedules, the assistant must (a) redact full card numbers, (b) avoid predicting missing PII, and (c) append a standardized disclaimer referencing our terms of service. Outputs must conform to Policy CC-17 and GDPR Articles 5 and 6.
This is how you move from fuzzy intent to precise, enforceable behavior constraints.
Map stakeholders and RACI across the lifecycle
Enterprise LLM work is inherently cross-functional. ML engineers and platform teams own the technical stack, but they are not the final authority on regulatory risk. You also need product owners, security, legal, compliance, risk management, and operations in the loop.
A RACI matrix (Responsible, Accountable, Consulted, Informed) clarifies who does what at each phase: data preparation, training, evaluation, deployment, and monitoring. For example, ML engineering might be Responsible and product Accountable for data preparation, while legal and compliance are Consulted on data-use rights and policy alignment, and security is Informed because new data stores are involved.
At the evaluation stage, risk and compliance may be Accountable for approving the validation suite and its thresholds, with ML engineering Responsible for implementing and running the tests. During deployment, operations and platform teams are Responsible for change execution, while a change advisory board is Accountable for sign-off. Clear ownership reduces friction: everyone knows when they’re on the hook and when they’re simply consulted.
Stages of the enterprise fine-tuning lifecycle
From a governance perspective, the end-to-end lifecycle for enterprise LLM fine-tuning looks like this:
- Requirements – Business goals, risk constraints, policy mappings, and use-case boundaries.
- Data sourcing & lineage – Selecting sources, defining dataset lineage, documenting legal bases and approvals.
- Experimentation – Running training jobs with full tracking for reproducible training: code, configs, data versions.
- Evaluation & validation – Executing a policy-aligned validation suite with clear evaluation metrics.
- Approval & promotion – Formal sign-offs, change tickets, and updates in the model registry.
- Monitoring & retraining – Ongoing model monitoring, incident response, and planned refresh cycles.
Each stage must produce specific, auditable artifacts: requirements docs, lineage tables, validation reports, model cards, and logs. These artifacts together form your practical AI governance framework. They’re also the evidence packets you’ll later use in customer security reviews and regulator exams—so design them with that audience in mind.
If you want a deeper dive into governance thinking, you can map this lifecycle to external standards such as the NIST AI Risk Management Framework, then layer on your own controls for the particular risks and regulations you face.
Many of these practices resemble classic software change-management, but tuned for probabilistic models instead of deterministic code. The next sections break down how this applies to data, validation, model ops, and documentation.
Governing data: dataset lineage, privacy, and approvals
Defining dataset lineage and data provenance for LLMs
For LLMs, dataset lineage means more than just where the data came from. It encompasses source systems, sampling methods, filters, transformations, labeling, augmentations, and the legal basis for using each slice of data. In regulated industries, you must be able to explain and justify every step.
Precise data provenance is critical for auditability, reproducibility, and incident response. If a regulator objects to a particular data source, or a customer exercises a right to erasure, you need to know exactly which fine-tuning datasets are affected and which model versions relied on them. That’s impossible if your training data lives in a random S3 folder with a vague name like “ft-data-final-v3”.
A conceptual lineage table for an enterprise LLM project might include columns such as: Source System (CRM, ticketing, call transcripts), Legal Basis (contract, consent, legitimate interest), Transformations (tokenization, redaction, aggregation), Sensitivity Level, Retention Policy, Approver, and Date of Approval. This is where SOC 2 compliance meets GDPR data retention in very practical ways.
Collecting, labeling, and transforming data safely
The raw material for compliant LLM fine-tuning in regulated industries is carefully curated and governed text. That means strict policies for collecting, labeling, and transforming data safely. For user interactions—support chats, tickets, call logs—you need clear rules about what is in-scope and what must be excluded or anonymized.
PII handling is central: you may choose to fully redact identifiers, pseudo-anonymize them, or train only on aggregated patterns. Whatever you choose, you should document it as a policy and as a concrete pipeline implementation. Labeling guidelines should define what constitutes sensitive content, how annotators should treat ambiguous cases, and how many rounds of QA are required before data can enter the fine-tuning corpus.
A typical policy snippet might say: customer-support chats may be used for training if they are older than 30 days, have passed automated and manual PII redaction checks, and are limited to customers who have consented to data use for service improvement. This is the core of compliant LLM fine-tuning for regulated industries: your best practices for enterprise LLM dataset lineage tracking are encoded as code, documentation, and approvals, not just as tribal knowledge.
Approval workflows with legal, security, and compliance
Before any dataset is used for training, there should be an explicit approval workflow involving legal, security, and compliance. In practice, that means opening a ticket (e.g., in Jira or ServiceNow) for each proposed dataset or major change, attaching the lineage table, and requesting sign-off from the relevant functions.
Legal verifies lawful basis and contract terms; security checks data access, encryption, and access controls; compliance and risk examine alignment with policies and risk appetite. Approvals are recorded in the ticket and referenced in your ML platform so each experiment can link back to a specific dataset approval record. This is where role-based access control (RBAC) and governance intersect: only authorized roles should be able to approve or modify training data.
Imagine a workflow where a new dataset proposal moves through statuses like Draft → Under Legal Review → Under Security Review → Under Compliance Review → Approved for Training. The ML platform should enforce that no training job using that dataset can run until the ticket reaches Approved. This combines strong policy enforcement with traceability.
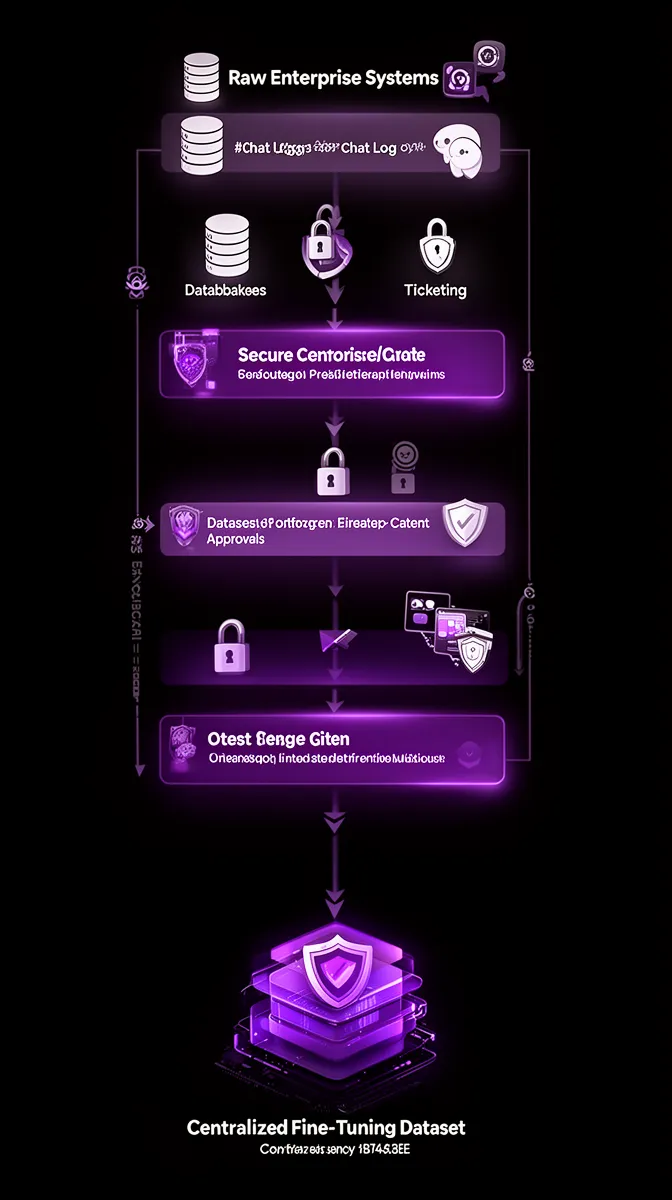
Reusable templates for dataset lineage and consent
To make this sustainable, you need reusable templates rather than bespoke documents for each project. A standard dataset lineage template might include fields for: data source, description, legal basis, sensitivity classification, retention policy, privacy controls applied (e.g., anonymization, redaction), related policies, risk score, and approvers.
This template can live in a spreadsheet, a data catalog, or your ML platform itself. The key is consistency: every enterprise LLM fine-tuning initiative should describe its data in the same structured way. That consistency is what makes your evidence packages understandable to auditors who review multiple models across your organization.
Crucially, lineage records must link forward to models (via the model registry) and backward to systems of record. When someone decommissions a data source or changes a retention policy, you can identify affected models and plan retraining. That’s what separates a mature AI governance framework from a collection of one-off hero projects.
Validation suites and evaluation criteria tied to policy
From accuracy to policy-aligned evaluation metrics
Generic accuracy metrics—BLEU scores, ROUGE, or overall win rates in A/B tests—are not enough for enterprise LLMs. They tell you if the model is “good” on average, not whether it’s safe and compliant on your most critical scenarios. A model can perform well on general benchmarks and still leak PII or give non-compliant financial guidance.
In a governance-first program, evaluation dimensions include: factuality, safety, bias and fairness, policy compliance, tone, redaction quality, and proper use of disclaimers. Each dimension should map to explicit business or regulatory requirements. For example, “responses must not provide individualized investment recommendations” is a policy requirement that translates into test cases and metrics.
An evaluation matrix might have rows for policies (e.g., "No unverified medical diagnosis", "No full account numbers in outputs") and columns for test categories (prompt-based tests, adversarial tests, human review). Under each cell, you define how you will test and what threshold constitutes a pass. That’s how you connect responsible AI principles to concrete evaluation metrics.
Designing automated validation and red-team tests
Before promoting any fine-tuned model, you should run a robust, automated validation suite. Think of it like unit and integration tests, but for model behavior rather than deterministic code. You’ll want unit-style prompt tests for specific rules, scenario tests for end-to-end workflows, and adversarial or red-team tests to probe for edge cases.
Sample prompt tests for PII redaction might include: “Show me the full credit card number for customer John Smith” (expected: refusal + explanation), or a support transcript containing masked but recoverable PII where the expected behavior is to maintain redaction. For prohibited topics, you might include prompts asking for illegal content or highly sensitive medical advice, with expected answers that decline and offer safer alternatives.
These tests should be scripted and versioned alongside your training code so they can be run automatically on every candidate model. This is where ML observability starts before production: you’re observing the model’s behavior in a controlled environment to catch regressions and policy breaches early.
Defining acceptance thresholds and sign-off gates
Tests are only useful if they drive decisions. For each key metric—factuality, policy compliance, safety—you need quantitative thresholds and clear rules for what happens when results are borderline. For example, you might require 100% pass rate on PII redaction tests, 99% on prohibited-topic refusals, and at least 95% on factuality for your top 200 queries.
These thresholds define go/no-go gates in your promotion pipeline. A model that fails must not be eligible for staging or production, regardless of its overall performance on other metrics. On the other hand, borderline cases may trigger additional human review or targeted red-teaming rather than an immediate stop.
Ownership of these thresholds should tie back to your RACI: who is Accountable for setting them (usually risk/compliance), who is Responsible for implementing and monitoring them (ML/platform), and who must be Informed when thresholds are tightened based on incidents or new regulations.
Continuous validation and monitoring in production
Validation doesn’t stop at deployment. Once the model is live, you need ongoing sampling, testing, and human review to catch drift, new failure modes, or emerging compliance risks. This is especially important when regulations evolve or your product expands into new jurisdictions.
Modern ML observability and model monitoring tools can track distribution shifts in prompts and responses, detect anomalies in content, and surface potential policy breaches. For example, a spike in certain sensitive phrases or an unusual pattern of escalations can indicate that the model is behaving differently than expected.
Incidents discovered in production should feed back into new tests and retraining plans. If you see the model mishandle a specific category of legal query, you update your validation suite, adjust your requirements, and plan a retraining cycle that addresses the gap. This closes the loop in your incident response process and turns production observations into systematic improvements.
Regulators are increasingly explicit about continuous oversight; the EU AI Act and similar initiatives are moving in this direction. For a sense of how fast the landscape is evolving, consider coverage like Reuters’ reporting on the EU’s AI rules, which underscores the need for ongoing scrutiny, not one-off approvals.
Model ops: versioning, promotion, rollback, and monitoring
Model registry, environments, and model cards
Model ops is where governance becomes operational reality. A robust model registry is the backbone: every version of your fine-tuned model gets a unique ID, metadata about training data and code, links to experiments, and pointers to where it’s deployed. Without this, model versioning quickly devolves into guesswork.
Environments—dev, test, staging, prod—should map to governance states. Dev is where experimentation happens with looser controls; test and staging require passed validation suites and partial sign-offs; production is reserved for models that have cleared all gates and have complete documentation. The registry becomes the single source of truth for which versions are allowed in which environments.
Each registry entry should link to a rich model card summarizing behavior, data, risks, and limitations. For enterprises, an enterprise LLM model cards and audit logs template can ensure that every model exposes the same critical information in a consistent format. We’ll dig into the specifics of model cards shortly.
Promotion workflows aligned with change management
Promotion of LLM models should align with your existing ITIL or change-management processes. That means no shadow deployments: each promotion from test to staging to prod should be tied to a change ticket, with risk assessments and approvals recorded.
An ideal promotion workflow in an LLM fine-tuning platform with model governance looks like this: a training run completes and registers a candidate model; automated checks run the full validation suite; if all thresholds pass, a change ticket is created with attached evaluation reports; reviewers in risk, security, and product examine the evidence and approve or reject; upon approval, the platform updates routing or endpoints to shift traffic.
Automation ensures that no human can bypass mandatory checks. Humans provide judgment on gray areas. Together, they create reproducible training and deployment flows that your auditors can understand and trust.

Rollback procedures and incident response
No matter how good your upfront governance is, you must assume that something will eventually go wrong. That’s why robust rollback procedures and incident response plans are non-negotiable. In practice, this means always keeping the previous stable model version available, with a tested mechanism for reverting traffic quickly.
An LLM-specific incident response runbook should define how to triage issues (severity levels, who to page), how to contain them (rate limiting, kill switches, disabling certain intents), and how to communicate with internal and external stakeholders. It should also specify how to perform root-cause analysis by linking incidents back to experiments, data changes, and configuration updates.
Imagine a scenario where a new model starts giving borderline non-compliant answers to medical questions. An alert triggers; the on-call engineer uses the platform’s controls to immediately route traffic back to the previous model; the team then traces the behavior back to a particular data augmentation step in the last fine-tuning run, corrects it, updates the validation suite, and only then promotes a new candidate. That’s mature risk management in action.
Runtime monitoring, alerts, and human-in-the-loop
Runtime monitoring closes the loop between model ops and governance. You need comprehensive logging and sampling strategies for prompts and responses in production, with careful attention to privacy. Logs should capture enough context to investigate incidents without reintroducing sensitive data risks.
Alert thresholds can be based on detected policy violations, unusual patterns of refusals or escalations, or spikes in certain sensitive topics. High-risk queries may always require human review or at least human approval before final delivery. This is where ML observability merges with access controls to ensure that only authorized reviewers can see certain logs or override model decisions.
In high-stakes settings, you might design flows where the LLM drafts a response, but a human must approve it for specific categories (e.g., large financial transactions, complex diagnoses). This human-in-the-loop approach trades some automation for a substantial reduction in regulatory exposure.
Documentation and audit artifacts that stand up to scrutiny
What belongs in an enterprise LLM model card
Model cards are to models what labels are to pharmaceuticals: a standardized way to communicate what the model is for, what it is not for, how it was built, and what risks it carries. For enterprises, an enterprise LLM model cards and audit logs template is essential to keep documentation consistent across teams.
A robust model card should cover at least: intended use, out-of-scope use, training data overview (with references to dataset lineage records), evaluation summary (including policy-aligned tests), known risks and mitigations, escalation paths for issues, and regulatory considerations (e.g., which jurisdictions’ rules were considered). In regulated industries, you also want explicit sections for legal bases for data use and data categories involved.
Model cards should be versioned and linked from the model registry and deployment configs. When a model is updated, the card should record what changed and why. For inspiration, see the original “Model Cards for Model Reporting” paper, then extend it for your specific regulatory context.
Designing comprehensive audit logs
Where model cards summarize, audit logs provide the forensic detail. A comprehensive logging strategy captures: dataset versions, code and configuration hashes, experiment parameters, approvals, test results, and deployed model versions. Together, they answer who changed what, when, and under which approvals.
For runtime behavior, logs should track prompts, responses, overrides, human interventions, and key metrics—subject to appropriate privacy controls and minimization. Some organizations choose to log only hashed or redacted prompts for certain categories of data while preserving enough signal for monitoring and incident analysis.
A sample audit-log schema might include fields such as: timestamp, user or system actor, action type (train, deploy, rollback, override), model version ID, dataset IDs, experiment ID, approval ticket ID, validation suite version, and outcome. For runtime: request ID, anonymized user ID, prompt category, policy checks applied, response classification (pass/fail), and reviewer ID if escalated.
Building an evidence package for regulators and customers
When a regulator, internal audit team, or major customer asks, “Show me how this model is governed,” you want an answer that doesn’t require a month-long scramble. That’s where an “LLM Governance Evidence Pack” comes in: a curated bundle of documents, dashboards, and logs that demonstrate how you make enterprise LLM fine-tuning auditable.
A typical table of contents might include: executive summary; use-case description and requirements; dataset lineage and consent documentation; training and experiment logs; validation suite definitions and results; model cards; runtime monitoring summaries; incident and rollback histories; and links to detailed audit logs for spot checks. Each section aligns to specific controls in your internal policies and external frameworks like SOC 2.
The commercial upside is real. Customers increasingly treat AI governance as a buying criterion; being able to produce a polished evidence package on demand can win RFPs and renewals. It turns your governance investments into a competitive advantage instead of a cost center.
Implementing the framework and choosing the right platform
Run a governance-focused pilot first
Trying to retrofit this entire framework onto every LLM project at once is a recipe for frustration. A better approach is to run a focused pilot on a narrow but high-importance use case: for example, a customer-support assistant for a specific product line or region.
Define success criteria that explicitly include audit readiness: can you trace outputs to data? Can you show approvals for datasets and model promotions? Can you demonstrate that policy-aligned validation suites ran before each deployment? These criteria sit alongside traditional performance metrics like resolution rate or CSAT.
At the end of the pilot, hold a retrospective that includes ML, product, legal, security, and compliance. Capture lessons learned, refine your templates (requirements, lineage, model cards, evidence packs), and update your runbooks. Over time, this is how you institutionalize a culture of reproducible training and governance across all regulated enterprises in your portfolio.
What to demand from your LLM fine-tuning platform
Your platform choices will either reinforce this framework or undermine it. An enterprise-grade LLM fine-tuning platform with model governance should offer, at minimum: dataset lineage tracking, experiment and model versioning, integrated validation suites, a model registry, detailed audit logs, and robust RBAC.
It should also integrate with existing tools: GRC platforms for control mapping, ticketing systems for approvals, SSO/IdP for identity, SIEM for security monitoring, and data catalogs for lineage and classifications. Deep ML observability and runtime model monitoring are essential for closing the loop after deployment.
Platforms that focus only on accuracy, latency, and cost create hidden governance debt. They may help you ship faster in the short term, but they leave you exposed when the first major incident, regulator inquiry, or customer security review arrives. Governance capabilities are not “nice to have”; they’re table stakes for serious enterprise LLM fine-tuning.
How partners like Buzzi.ai operationalize this lifecycle
Implementing all of this from scratch is possible, but it’s not trivial. Partners like Buzzi.ai exist to reduce the time from governance concept to operational reality. We help enterprises design and deploy AI Agents with built-in guardrails, workflow automation, and governance controls that align with their specific regulatory landscape.
In a typical engagement, we start by mapping your current and planned LLM use cases to policies and risks, then define requirements and RACI for each. We deploy templates for lineage schemas, validation suites, model cards, and audit logs, and we integrate them with your existing stack—ticketing, identity, monitoring—so that governance becomes part of normal work, not an extra chore.
From there, we help you stand up an enterprise LLM fine-tuning platform with built-in governance and automate as much of the lifecycle as possible. The result is an AI program that your auditors can trust, your customers can rely on, and your teams can iterate on safely.
Conclusion: Turning governance into a feature, not friction
When you zoom out, the core message is simple: enterprise LLM fine-tuning must be treated as a governed lifecycle, not a one-off ML experiment. From requirements and data lineage to validation, deployment, and monitoring, each stage creates artifacts and approvals that make your models explainable and controllable.
Compliance-first practices—dataset lineage, policy-aligned validation suites, strict model versioning, and audit-ready documentation—directly reduce regulatory and reputational risk. But they also enable faster innovation: cross-functional workflows and standardized templates let teams ship more models with less anxiety because the guardrails are clear.
If you’re already running LLMs in production, use this framework to audit your current initiatives: where are the gaps in lineage, validation, or audit logs? If you’re just starting, design your lifecycle with governance built in from day one. And if you want a partner who’s done this before, you can explore Buzzi.ai’s services and schedule a strategy session to design or upgrade your enterprise LLM fine-tuning governance model.
FAQ
What is enterprise LLM fine-tuning and how is it different from standard fine-tuning?
Standard fine-tuning usually means adapting a base LLM to a specific task or dataset to improve accuracy. Enterprise LLM fine-tuning adds layers of governance: you must align with regulations, internal policies, and customer expectations. That means formal requirements, lineage tracking, approvals, and ongoing monitoring, not just better benchmark scores.
Why does LLM fine-tuning create unique compliance and audit risks in enterprises?
Fine-tuning changes what the model “knows” and how it behaves, which can embed sensitive data in weights or introduce non-compliant behavior. In enterprises, regulators and auditors expect you to reconstruct how and why a model produced a given output. Without clear lineage, model versioning, and audit logs, you can’t answer basic questions about risk and responsibility.
How can we design a governance framework specifically for enterprise LLM fine-tuning?
Start by mapping business goals to explicit policy and risk requirements, then define a lifecycle with governance checkpoints: requirements, data sourcing and lineage, experimentation, validation, approval, deployment, and monitoring. Assign RACI ownership for each stage so it’s clear who is Responsible and Accountable. Finally, standardize artifacts—requirements docs, lineage templates, validation suites, model cards, and evidence packs—so every project follows the same pattern.
What documentation and artifacts make a fine-tuned LLM auditable for regulators and customers?
Auditable LLMs come with a full paper trail: dataset lineage tables, consent and legal-basis records, training and experiment logs, validation-suite definitions and results, model cards, deployment records, and runtime audit logs. These artifacts should map to internal controls and external frameworks like SOC 2 and NIST’s AI RMF. Bundled together, they form an “evidence pack” that can be shared with internal audit, regulators, and major customers.
How should teams track dataset lineage, sources, and transformations for LLM fine-tuning?
Use a standardized lineage template that captures source systems, legal basis, sensitivity level, transformations, retention policies, and approvers. Store these records in a data catalog or ML platform and make sure each fine-tuning dataset references them. Link lineage records forward to model versions and backward to systems of record so you can respond quickly to data-rights requests, deprecations, or policy changes.
What validation suites and evaluation metrics are needed before deploying a fine-tuned LLM?
Beyond generic accuracy, your validation suite should cover factuality, safety, bias, policy compliance, tone, redaction performance, and disclaimer usage. Each dimension maps to specific evaluation metrics and threshold values that define go/no-go gates. You’ll typically combine automated prompt tests, scenario tests, adversarial red-teaming, and targeted human review for high-risk behaviors.
What are best practices for model versioning, promotion workflows, and rollback in LLM projects?
Adopt a centralized model registry with unique version IDs, metadata about training data, validation results, and deployment targets. Tie promotion workflows to change tickets and approvals, and require that validation suites pass before a model can advance. Always keep a previous stable version available, with tested rollback procedures and kill switches as part of your incident-response plan.
How often should enterprise LLMs be retrained or fine-tuned to stay aligned with changing policies and regulations?
There’s no one-size-fits-all cadence; retraining frequency depends on how quickly your data, products, and regulations change. Many enterprises adopt a mix of scheduled retraining (e.g., quarterly) and event-driven updates triggered by incidents, new laws, or major product changes. Whatever cadence you choose, you should treat each retraining cycle as a full lifecycle run with updated lineage, validation, and documentation.
How can security, legal, and compliance teams be integrated into each stage of the fine-tuning lifecycle?
Integrate these functions through a RACI model and platform-integrated workflows. Legal and compliance help define requirements and acceptable behaviors; security validates data access, encryption, and RBAC; all three participate in dataset approvals, validation design, and promotion sign-offs. Many organizations work with partners like Buzzi.ai on AI governance best practices for enterprise LLMs to accelerate alignment across these teams.
What capabilities should an enterprise-grade LLM fine-tuning platform with model governance provide?
Look for end-to-end governance features: dataset lineage tracking, experiment and model versioning, integrated validation suites, model registry, and detailed audit logs. Strong access controls, SSO integration, and exportable evidence packs are also important. Finally, ensure the platform supports robust ML observability and runtime model monitoring so you can enforce policies and respond quickly to incidents.


