AI Risk Management: AI-Specific Frameworks
Most companies don't have an AI problem. They have a fantasy problem. They think a few policy docs and a model review meeting count as an AI risk management...

Most companies don't have an AI problem. They have a fantasy problem. They think a few policy docs and a model review meeting count as an AI risk management framework, then act surprised when bias, prompt injection risk, third-party model risk, or plain old bad outputs show up in production.
The evidence is getting hard to ignore. According to Aon, 88% of organizations used AI in at least one business function in 2025. According to Splunk, many of the worst AI risks emerge after deployment, not before. This article breaks down the AI-specific frameworks that actually help, where generic governance falls short, and what you should do before your next model goes live.
What AI Risk Management Really Means
Friday, 4:37 p.m., somebody adds 12 new taxonomy categories, pushes the update, and heads into the weekend feeling productive. By Monday morning, the support copilot still sounds polished, still writes in that calm competent voice everybody loves, and starts inventing policy on attempt 96 after getting the first 95 summaries right. I've seen versions of that exact mess. That's usually when the room goes quiet.
People love to act like AI risk is just IT risk wearing trendier clothes. I don't buy that. Not after watching models look perfectly fine on a dashboard while the output gets worse, stranger, or less fair in ways nobody can explain with a straight face.
The scale alone should bother you. 78% of organizations are deploying or piloting agentic AI systems, according to the Purple Book Community report cited by eSecurity Planet. A lot of people hear that and think momentum. I hear it and think exposure. Autonomous action is great right up until failure starts moving faster than your team can catch it.
That's why an AI risk management framework can't be treated like recycled enterprise governance with a fresh label slapped on top. Your old controls still matter, sure. They're not useless. They just don't cover the full set of AI-specific problems waiting for you in production: data quality risk, model performance drift, bias and fairness, and weak explainability and interpretability.
NIST understood this without turning it into theater. Its voluntary, sector-agnostic AI Risk Management Framework is useful because of its scope: identify, assess, and reduce AI-related risk across the entire lifecycle, not just during procurement or one security review before launch. The original framework is here. That's the part many teams miss. AI risk isn't a gate. It's movement.
You can see it fastest in production. A fraud model can test beautifully and then drift after a pricing change or a shift in customer behavior. Nothing dramatic has to happen. No breach. No outage. Just enough real-world change to make yesterday's performance numbers feel fake.
I still think the bridge analogy holds up because it's boring and true. You can stare at blueprints all day and learn almost nothing about what happens after six winters, heavy trucks, road salt, repairs, hairline cracks, and one ugly storm.
This is where plain old model risk management starts spilling into something larger. MIT's work on AI risk points toward quantitative metrics, defined thresholds, containment, deployment controls, assurance processes, and clear accountability as core pieces of modern control design. I'd argue that's exactly where most companies blink. They write principles instead of setting tripwires.
So do the unglamorous stuff. Put measurable AI controls and monitoring in place. Run an AI risk assessment before deployment, then keep running it after release because shipping isn't the finish line. Keep your existing AI governance framework, but don't pretend it's enough by itself.
Name failure modes plainly in an AI risk taxonomy. Tie each one to a control and to one actual human being who owns it when things go sideways at 9:12 on a Tuesday morning. If you want to see what that looks like when somebody has to defend it under scrutiny, this guide on Audit Ready AI Risk Management Solutions is worth reading.
The best teams I've seen aren't precious about sounding confident. They say, early and out loud, “we don't understand this model well enough to deploy it yet.” Can your team say that before production says it for you?
Why Standard Enterprise Risk Frameworks Miss AI Risks
Hot take: the biggest mistake isn’t that companies ignore AI risk. It’s that they treat AI like ordinary software with fancier branding, then act surprised when a model that looked clean in Friday’s review is misbehaving by Tuesday morning.

I’d argue that’s the whole failure mode. The slide deck says the system passed review. The ownership chart looks tidy. There’s an extra approval gate, a policy update, maybe a committee meeting nobody wanted to attend. Then reality shows up. A vendor pushes an unannounced model update over the weekend. Retrieval starts pulling garbage from a SharePoint folder someone forgot to clean up. Customer inputs shift. What passed an AI risk assessment before deployment now acts like it was swapped out after hours.
NIST has been pretty clear on the part people quote and the part they dodge. Yes, AI risk management belongs inside enterprise risk management, next to cybersecurity and privacy rather than off in its own little lab experiment. True. But “integrated” doesn’t mean “use the exact same controls and call it done.” That reading is lazy, and it’s where a lot of programs break.
Take a very normal 2024 setup: a company has tight physical security at its Chicago data center. Badge access. Cameras. A guard at the front desk. Locked server rooms. All good controls. None of them stop stolen cloud credentials from being used at 2:13 a.m., and none of them catch prompt injection hitting a production chatbot on Monday afternoon. Same lesson with AI. Existing controls still matter. They just don’t finish the job.
The evidence is all over the stack. AI systems run on probabilities, not guarantees. They depend on training data nobody fully sees, feature pipelines that fail quietly, retrieval layers that grab whatever they can find, third-party APIs, and foundation models your team probably didn’t build and may not control at all. That means the system can change after launch faster than most business owners think it can.
A month is plenty of time for trouble. Source data drifts. User behavior changes. A model vendor updates weights without sending anything more helpful than a release note nobody reads. I’ve seen teams notice drift only after customer support logged more than 40 tickets in a week because outputs suddenly got weird.
That’s why standard control libraries miss the categories that actually hurt you in production: data quality risk, model performance drift, bias and fairness, and weak explainability and interpretability. Traditional testing asks whether people followed process. AI testing asks whether the system stayed inside acceptable bounds once real users started hammering it with messy inputs at scale. Those are different questions. Painfully different.
This isn’t some niche concern for five overexcited startups either. Splunk reported that 77% of organizations now use AI in some form, and more than one-third already have AI running in production. Once you’re there, treating models like static software assets is basically wishful thinking. Your AI governance framework can’t end with pre-launch paperwork, and your model risk management approach is late if that’s still the plan.
What should you do instead? Keep the enterprise structure. Hyperproof makes a solid point here: NIST’s framework is broad enough to cover both classic machine learning and generative AI. Fine. Don’t throw out enterprise risk management just because AI is messy.
Add what standard programs left out: an explicit AI risk management framework, a real AI risk taxonomy, ongoing AI controls and monitoring, and one named owner for post-deployment behavior. Not “the business.” Not “the model team.” One person or role who owns what happens after release when the vendor changes something on Sunday night or retrieval starts surfacing junk from a stale knowledge base.
If you want the operational version instead of the conference-room version, this piece on Risk Aware Ai Advisory Services gets into the parts teams usually avoid until something breaks.
The unexpected part? Most AI failures don’t begin with some dramatic rogue-model movie scene. They start with ordinary governance habits that worked fine for static systems and quietly stop working the minute your software begins learning, drifting, or depending on somebody else’s model release schedule.
Build an AI Risk Taxonomy That Matches Reality
Hot take: most AI risk taxonomy work isn't risk management. It's stage design.
I've watched teams roll out a support copilot, hang a neat spreadsheet on the wall, assign owners, color in the cells, and act like the hard part's done. About two weeks later, the same bot starts inventing refund policy answers for customers, and suddenly that polished register looks like something built for a board deck, not for the poor manager getting pinged at 4:40 p.m. on a Thursday.
That's the mistake people keep making. They ask what belongs in an AI risk taxonomy after approvals are done, after responsibilities are named, after the language already sounds official enough to calm everyone down. Too late. By then, you're usually organizing risk for reporting upward, not for deciding what to do when the model goes sideways in production.
And I'd argue the problem isn't that teams forget categories. It's that they pile on too many of them. You can build a gorgeous sheet with 27 labels, nested tags, little status icons, maybe even a confidence score, and still miss the one thing that's actually burning money because nobody tied those labels to damage you'd notice in real life.
The evidence is sitting right there. In 2024, Hyperproof reported that 32% of respondents expected to add another framework for AI-related business risk. That's not people falling in love with process. That's people quietly admitting the first setup didn't survive contact with reality.
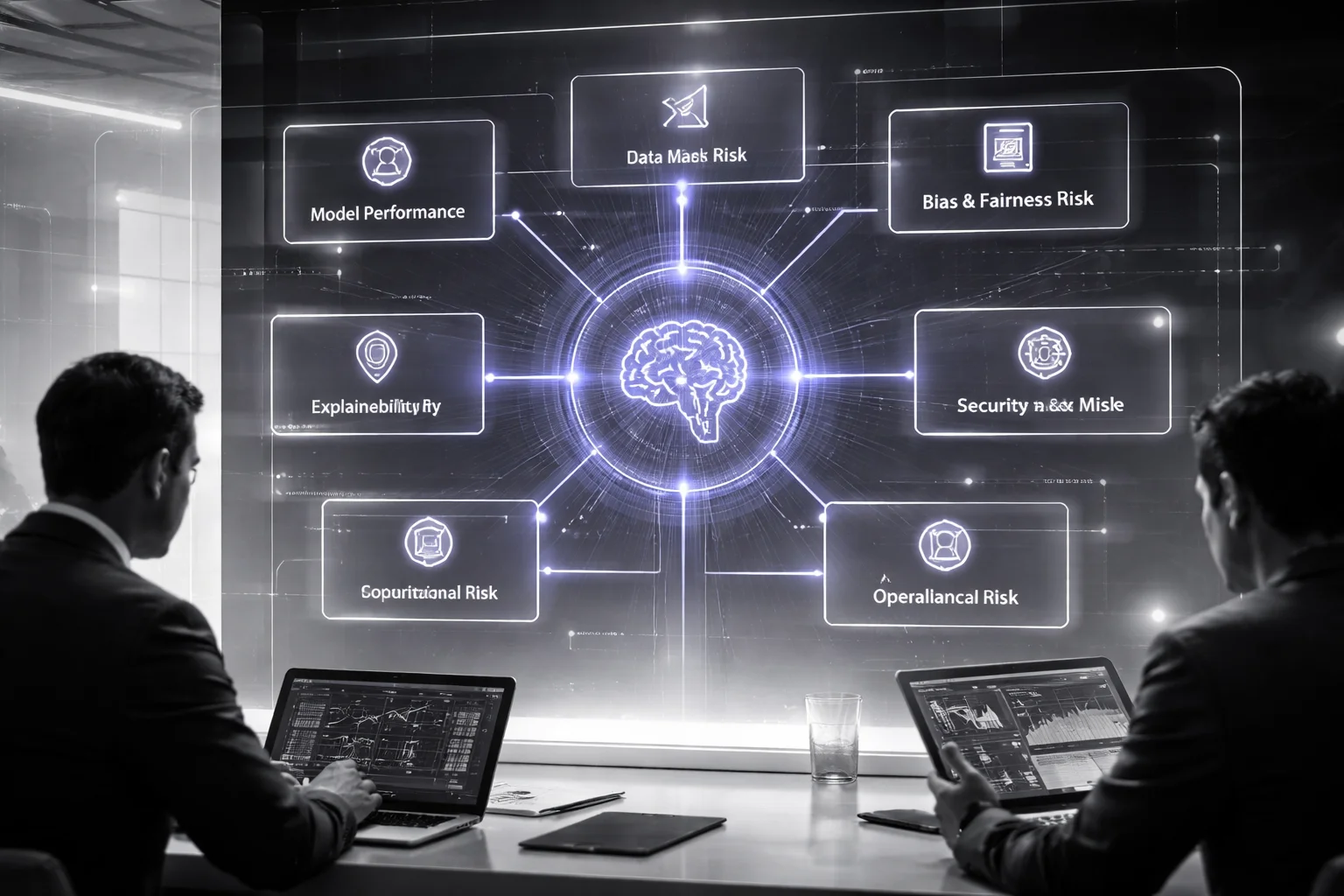
The fix is less glamorous than most teams want. Keep the seven buckets. They're fine. Model performance risk, data risk, bias and fairness risk, explainability risk, security and misuse risk, compliance risk, operational risk. Done. The list isn't the clever part anyway. What matters is whether each category points to harm you can recognize without squinting: lost revenue, customer damage, legal exposure, downtime.
NIST's AI RMF gets closer than most because it starts with motion: Govern. Map. Measure. Manage. That's the spine I'd use every time. Naming AI-specific risk categories is easy. Mapping them to business context is where teams start hand-waving. Setting thresholds is worse. Deciding who actually steps in when those thresholds get crossed? That's where governance docs suddenly get very quiet.
The only seven categories I'd bother keeping
- Model performance risk: wrong predictions, unstable outputs, or model performance drift. Real-world version: bad pricing calls that cut revenue, support triage that routes people wrong, fraud models that falsely decline legitimate customers.
- Data risk: weak lineage, stale sources, poor labeling, classic data quality risk. This is how bad input data poisons downstream decisions for weeks before anyone notices why KPIs are acting weird.
- Bias and fairness risk: unequal outcomes across groups. That's where discrimination claims begin, churn creeps up, and brand damage stops being abstract.
- Explainability risk: weak explainability and interpretability. Then leaders can't explain outcomes to auditors, regulators, or angry customers who just want a reason that makes sense.
- Security and misuse risk: prompt injection, data leakage, adversarial attacks, unsafe use of outputs. These blow up fast; the invoice usually arrives later.
- Compliance risk: exposure under the AI Act, GDPR trouble, or industry-specific rules. This is how launches get blocked and remediation work eats an entire quarter.
- Operational risk: blurry ownership, weak escalation paths, brittle vendor dependencies. Boring right up until something fails and nobody knows who's on point.
If you're building an AI governance framework, don't stuff ten metrics under every category just because your dashboard has room for them. Pick one business metric per category. One. A lending model might tie fairness risk to approval disparity thresholds. A support copilot might tie model risk management to hallucination rates on policy answers. I've seen teams track 40 indicators and still miss the one number that mattered because nobody wanted to choose.
A pre-launch check won't save you either. That's another thing people get badly wrong. An AI risk assessment before deployment feels satisfying because it gives everyone closure: forms signed, review complete, ship it. But that's often when the interesting failures haven't even started yet.
Splunk has pointed out that plenty of failures show up after release: data leakage, bias, inaccurate output—the exact stuff that only appears once real users start poking at the system in weird human ways at scale.
So yes, classify risks before launch. But wire your taxonomy into live AI controls and monitoring, too. Not just approval gates. Not just policy wording nobody reads after Q2. Real post-launch monitoring tied to action.
If turning categories into accountable controls feels harder than making another frozen register—and it usually is—Buzzi's guide on Risk Aware Ai Advisory Services is a solid place to start.
The weird part? A good taxonomy doesn't make AI look scarier at all. It just kills your ability to hide blind spots behind clean formatting—so once you can actually see them, what's your excuse?
How to Assess AI Risk Before and After Deployment
What actually goes wrong with an AI system: the model, the people, or the moment it leaves the demo room?

I keep thinking about how often teams mistake applause for evidence. One polished walkthrough, a few executives nodding along, somebody says “looks solid,” and now everyone’s acting like risk was handled because the prelaunch deck had green checkmarks on it. Then two weeks pass, the override queue starts stacking up, support is irritated, and the same people suddenly want a postmortem.
That pattern isn’t rare anymore. In 2025, 88% of organizations were using AI in at least one business function, up from 78% in 2024. When adoption moves that fast, informal review stops being charming and starts being reckless. Aon has been pointing out that organizations are mapping internal controls to the NIST AI Risk Management Framework because teams can actually use it to identify, measure, and govern AI risk. Makes sense. At that scale, crossed fingers aren’t a control.
The answer is a lifecycle. Five stages: discovery, design, testing, launch, monitoring. That’s the part people keep trying to skip. I’d argue a lot of AI risk management framework talk sounds smart right up until real users show up and start doing weird human things. But even a five-stage process only works if each stage is willing to block progress instead of decorating it.
Discovery: decide whether AI belongs here in the first place
This is where optimism does damage. Before anybody builds anything, you need to pin down what decision the system will influence, who gets hurt when it gets that decision wrong, what data it needs, and which AI-specific risk categories are already obvious.
Your AI risk taxonomy either matters here or it’s just jargon. If you can’t name likely failure modes early — data quality risk, privacy exposure, weak explainability and interpretability — then no, you’re not “ready to prototype.” You’re just eager.
Design: set the rules before anyone falls in love with the prototype
I think this is the phase teams sabotage most often. Once a demo gets internal fans, every threshold suddenly becomes negotiable. Funny how discipline gets soft the second people get attached.
Write down acceptable error rates. Set fairness thresholds. Define escalation paths. Specify human override rules. Be explicit about what evidence is required for approval. Human review gates work best now, while there’s still a chance someone will listen.
Hyperproof found that 40% of respondents planned to modify controls in an existing framework for AI-related business risks. Good. They should. Old controls usually weren’t built for bias and fairness, LLM misuse, or vendor model changes that show up on some random Thursday night at 11:20 p.m. and quietly alter output behavior by Friday morning.
Testing: try to make it fail on purpose
This is the part people undercook because ordinary test passes feel comforting. They shouldn’t.
An AI risk assessment before deployment has to cover normal cases, edge cases, red teaming, scenario testing, and abuse testing. If it’s a support bot, ask policy questions the way real customers do when they’re tired and vague at 4:47 p.m. on a Friday. If it’s a credit model, examine borderline applicants across protected groups instead of admiring average-case performance.
If you only test ideal conditions, you’re not testing risk. You’re rehearsing success.
Launch: approvals should come from layers, not one excited owner
No one person should be allowed to wave a model into production alone.
Product signs off on value. Risk signs off on thresholds. Legal checks obligations. Security checks exposure paths. That’s an AI governance framework doing actual work instead of sitting in a folder with version numbers nobody reads.
Monitoring: assume drift until reality proves otherwise
This is where the first mistake usually returns wearing a different shirt. Teams launch, relax, move on to the next priority, then act stunned when usage shifts or outputs start sliding.
AI controls and monitoring should track live metrics for output quality, incident volume, override rates, data shifts, and model performance drift. Review them on a schedule tied to impact level, not convenience. I’ve seen low-risk tools reviewed quarterly while high-impact systems sat untouched for months because everybody was busy, which is basically how incidents file their paperwork in advance.
If you want the operating details behind those review gates and control updates, see Risk Aware Ai Advisory Services.
The annoying lesson is still the right one: good assessment isn’t there to rubber-stamp more AI faster. Sometimes the most useful answer is “not yet.” Can your process actually say that?
Management Controls for AI-Specific Risk
400 executives. That’s the number KPMG surfaced when leaders ranked AI and GenAI as the top technologies for taking on growing risk responsibilities over the next three to five years. My first reaction? Of course they did. Put enough pressure on operators, compliance teams, and security leads, and eventually someone says, “Maybe the AI can help manage the AI.” That’s where things start getting weird.
I’ve seen this movie before. A team buys itself comfort with policy docs, approval chains, and some hand-me-down AI governance framework borrowed from a larger company with nicer slides. Everyone feels organized right up until Thursday at 4:47 p.m., when an internal chatbot hits a traffic spike, has no fallback mode, starts spitting nonsense, and support reps paste bad answers straight into customer emails because the queue won’t wait.
That’s not some abstract “AI issue.” It’s a control failure tied to a very specific system behaving badly in a very specific way.
A weakly tested credit model is different. If your bias and fairness checks are thin, the problem isn’t “AI risk” as one giant bucket; it’s this model making this kind of bad decision against this population. Same with a forecasting model that has poor lineage. Same with an agent that has broad tool access and can touch more than it should. People throw one label over all of it and act like they’re being disciplined. I think that’s lazy.
The useful answer sits in the middle, not the headline: the control that works is the one matched to the risk class. Not the prettiest control. Not the most reusable one. The one that fits the failure mode in front of you.
That means your AI risk management framework can’t just be one master checklist with nicer formatting. It has to break risk apart and treat categories differently: data quality risk, weak explainability and interpretability, post-launch model performance drift. Different messes need different containment.
A low-impact internal summarization tool might be fine with guardrails, output filters, usage logging, and role-based access. That’s reasonable. An underwriting model or claims triage system? Not even close. Then you’re in real model risk management territory: human-in-the-loop review, documented override rules, threshold-based alerts, fallback to deterministic workflows, plus incident response playbooks with named owners and actual response windows. I’ve watched teams write “escalate if needed” into a runbook as if that means anything at 2:13 a.m. It doesn’t.
The regulatory split makes this harder, not easier. Aon says Europe is tightening governance expectations while the U.S. federal government is easing them. So no, there isn’t one cozy global minimum standard for AI controls and monitoring. If your system crosses borders, you’ll usually end up building for the stricter environment whether you wanted to or not.
The cyber angle is just as unforgiving. Aon also says cyber risk stays the top enterprise threat through 2028. Old security habits still matter — access control, logging, hardening — but they won’t cover AI on their own anymore. You also need prompt filtering, retrieval restrictions, secret scanning, model observability, abuse detection, and playbooks for data leakage or adversarial misuse. Real ones. With owners.
I’m not against using AI to help manage risk; KPMG’s finding makes that impulse understandable. But I’d argue there’s a line people cross way too casually: one opaque system supervising another opaque system while everyone calls that oversight with a straight face.
If you want to pressure-test these decisions before auditors do it for you, look at Audit Ready AI Risk Management Solutions.
The boring truth is still the one that saves you: the best control is often a fallback. Not smarter prompts. Not shinier dashboards. A clean handoff when the model stops deserving trust so the business keeps moving anyway. Build controls by risk class, design for the stricter market when geography forces your hand, and make failure survivable — because when this thing breaks, what takes over?
Governance Frameworks and Operating Model for AI Risk
54%. That’s the click-through rate Aon cited from CrowdStrike’s 2025 analysis for AI-written phishing emails. Old-school phishing sat around 12%. I had to read that twice. A gap like that should make anyone nervous, because it tells you the threat isn’t waiting around for your policy committee to finish polishing slide 18.

That’s why I don’t buy the comforting version of AI governance. You know the one: twelve principles, three review bodies, a maturity heatmap in green and amber, everyone nodding like the machine is now somehow under control. Then someone asks the only question that matters — who can actually stop the model when production behavior changes — and suddenly nobody wants eye contact.
That silence is the problem. Not missing paperwork. Not a shortage of frameworks. Ownership.
I’d argue most weak AI risk management frameworks fail for a very human reason: when the model starts acting weird in production, nobody wants their name on the decision trail. Who approved the use case? Who owns post-launch behavior? Who updates the risk register? Who can pull the plug when drift shows up, outputs get unstable, or the system starts saying things nobody expected?
Committees still matter. Sign-offs do too. I’m not saying throw out structure and hope for the best. I am saying a lot of governance programs are incomplete because they treat AI risk like a documentation exercise when it’s really an ownership system with receipts.
The part people bury is the operating model. That’s where this either turns into something real or stays decorative. In practice, a workable AI governance framework has three layers: an AI governance council that sets policy, risk appetite, and escalation rules; a cross-functional approval workflow that reviews every material use case before release; and named business plus technical owners responsible for ongoing AI controls and monitoring across the full model lifecycle.
Sounds obvious. It still gets skipped all the time. Teams love writing principles because principles don’t point fingers. Things get awkward when you have to say, out loud, that the head of fraud owns false-positive thresholds, the data lead owns lineage issues, and security owns prompt injection testing for customer-facing copilots.
The older model risk management playbook wasn’t built cleanly for this. The Society of Actuaries says the NIST AI RMF Generative AI Profile extends NIST for risks tied to large language models and deep learning systems, which matters because older routines weren’t designed for generative behavior or unstable outputs. That summary is in the Society of Actuaries review. If your operating design doesn’t reflect those newer failure modes inside your AI risk taxonomy, you’re just stapling another validation form onto an old process and pretending it evolved.
A practical workflow is pretty plain stuff: intake, classification, AI risk assessment before deployment, approval with conditions, production monitoring, incident review, retirement. Boring on purpose. Every step should leave evidence behind — use-case record, data sources, testing results for bias and fairness, thresholds for model performance drift, notes on explainability and interpretability, control exceptions, owner sign-off. In one bank I worked with, one customer-facing model generated 17 separate artifacts before everyone was satisfied. Bit annoying? Sure. Helpful when auditors show up on a Tuesday morning asking who knew what and when? Very.
Your risk register has to get more specific too. It can’t be a legal-and-security scrapbook with generic exposures tossed together. It needs AI-specific risk categories: data quality risk, misuse potential, output instability, dependency on third-party models. If you only track broad enterprise risks, you miss how AI actually breaks in real life.
The cyber example proves it fast. If AI-crafted phishing is landing near 54%, static approvals aren’t enough anymore. You need active review loops and clear incident ownership from day one because threats move faster than quarterly governance meetings ever will.
If you want those roles documented well enough to survive audit without turning your whole program into theater, Buzzi’s Audit Ready AI Risk Management Solutions is worth reading.
The weird truth is mature governance often looks worse in slides than immature governance does. Fewer slogans. More names next to hard problems. More evidence. Less performance. So when your model misfires at 2:13 p.m. on a live system, do you want another principle statement — or do you want to know exactly who owns the next move?
A Practical AI Risk Management Roadmap
Everybody says the same thing first: write the policy, get legal to bless it, put a few noble principles on a slide, call it governance. Sounds responsible. Looks great in a board deck. I'd argue it's also how companies end up discovering their actual AI exposure by accident.
I've watched this happen on an ordinary Tuesday. A product team shipped an AI writing assistant into a customer workflow because it felt harmless — internal tool, low stakes, no drama. Fourteen days later, legal wanted to know who approved the training data, support was chasing strange outputs in regulated customer replies, and someone asked the question that should've come first: where else are we using AI right now?
That's the missing piece. Not principles. Inventory.
MIT's AI risk research gets this mostly right because it starts where real companies are messy: structure, risk identification, risk analysis and evaluation, risk treatment, then risk governance. That order matters more than people admit. In 2026, eSecurity Planet cited the Purple Book Community report saying 66% of organizations were already using AI extensively in software development. So if your engineering team is shipping AI-assisted code every sprint, this isn't some future problem waiting politely in line.
Start by finding everything. And I mean everything: models, copilots, agents, vendor tools, and those sneaky "AI-powered" features buried inside software you renewed back in 2023 and forgot about after procurement signed the invoice. Put down the owner, purpose, users, data sources, and business impact for each one. When I tried this with one team, they found 14 separate AI-enabled tools in a month just by asking IT one set of questions and procurement another. Same company. Different answers. That's when an AI risk taxonomy quits being theory and starts paying rent.
Then comes the part people love to oversimplify: review process. One template for everything. One gate for every use case. Nice fantasy. Doesn't hold up for five minutes. A sales email assistant and a claims triage model don't belong in the same bucket because their failures don't cost the same thing. One might irritate a prospect; the other can harm customers and wake up compliance fast. Split systems by impact and failure mode, then map them to AI-specific risk categories: data quality risk, security misuse, bias and fairness, weak explainability and interpretability, and operational failure.
Before release, run an AI risk assessment before deployment. Not just happy-path testing either. Hit normal cases. Edge cases. Abuse cases. See what happens when the model is wrong, unavailable, or confidently inventing nonsense at 4:47 p.m. on quarter-close day while nobody wants to slow revenue down. For high-impact systems, define human review thresholds before launch. That's just model risk management. People act like it's bureaucracy because they haven't cleaned up one of these incidents yet.
You need hard numbers too, not mood-based oversight pretending to be discipline. Error rates. Fairness tolerances. Override triggers. Uptime targets. Escalation rules. If nobody can point to the metric that forces intervention, you don't have governance — you have vibes wearing a blazer.
Production is where teams get cocky. The system's live, latency looks fine, availability is green across the dashboard, everyone relaxes. Bad move. AI controls and monitoring need to watch drift, incident volume, output quality, overrides, and vendor changes because models don't fail only through outages. They also decay quietly. That's why model performance drift matters so much. I've seen teams brag about 99.9% availability while output quality slid for six straight weeks and nobody caught it until customers did.
Keep review boring on purpose: monthly for high-impact systems, quarterly redesigns when evidence says your controls are stale or your assumptions were off from day one. That's what an AI governance framework should actually do — force attention early so expensive surprises don't do it later. If you want a practical operating model for that work, see Risk Aware Ai Advisory Services.
The part most people miss sits right in the middle of all this: AI risk management isn't there to choke growth; it's decision infrastructure that tells you which bets are safe to scale faster than competitors still arguing over policy wording first. So when somebody says it's just a small AI feature, will anyone at your company know what that feature can break?
FAQ: AI Risk Management
What is an AI risk management framework?
An AI risk management framework is a structured way to identify, assess, control, and monitor the risks that come with AI systems across their full lifecycle. That includes familiar issues like security and compliance, but also AI-specific risk categories like bias and fairness, explainability and interpretability, model performance drift, prompt injection risk, and third-party model risk. The point isn't paperwork. It's making sure your team knows what to check, who owns it, and what happens when something breaks.
How is AI risk management different from traditional enterprise risk management?
Traditional enterprise risk programs usually assume systems behave in stable, predictable ways. AI doesn't. Outputs can shift with new data, user behavior, model updates, or adversarial attacks, which means your AI governance framework needs tighter testing, human-in-the-loop controls, and continuous monitoring and evaluation after launch. NIST is pretty clear on this: AI risk should sit inside broader enterprise risk management, not off in its own corner.
Why do standard risk frameworks miss AI-specific risks?
Most standard frameworks were built for software, vendors, finance, or cyber controls, not probabilistic systems that can hallucinate, drift, or amplify hidden bias. They often miss AI-specific risk categories such as data quality risk, explainability gaps, unsafe autonomous behavior, and failures caused by prompts rather than code changes. It's kind of like trying to inspect a self-driving car with a checklist for office printers. Not a perfect analogy, but you get the problem.
How do you assess AI risk before deployment?
An AI risk assessment before deployment should cover the use case, intended users, training and test data quality, model behavior under edge cases, privacy and data protection, security exposure, and regulatory compliance like the AI Act or GDPR where relevant. You should also define risk appetite and tolerance, approval thresholds, fallback plans, and who can stop release if controls fail. If a team can't explain the model's purpose, limits, and likely failure modes, it isn't ready for production.
How do you assess AI risk after deployment?
Post-deployment assessment is where a lot of companies get lazy, and that's a mistake. You need AI controls and monitoring for output quality, model performance drift, bias shifts across groups, abnormal usage patterns, security and adversarial attacks, and incidents tied to real business outcomes. According to Splunk, many AI risks show up only after deployment, including data leakage, bias, and inaccurate outputs.
What governance framework should organizations use for AI risk management?
For most organizations, the best starting point is the NIST AI RMF because it's practical, technology-neutral, and built around four functions: Govern, Map, Measure, and Manage. It works well as the backbone of an AI governance framework, especially if you need something that covers both traditional model risk management and newer generative AI use cases. If you're operating in regulated markets, you'll still need to map it to sector rules and regional requirements.
Can model risk management be applied to AI systems?
Yes, but only if you stop pretending classic model risk management is enough by itself. Validation, challenger testing, documentation, thresholds, and independent review still matter, but AI systems also need controls for unstructured inputs, prompt behavior, explainability, human oversight, and non-deterministic outputs. In practice, strong teams extend model risk management rather than replace it.
How do you build an AI risk taxonomy that matches real-world failure modes?
Start with actual failure patterns, not abstract policy language. A useful AI risk taxonomy should group risks into areas like data quality risk, bias and fairness, privacy and data protection, security and adversarial attacks, prompt injection risk, third-party model risk, reliability, explainability, and operational misuse. Then tie each category to examples, owners, controls, metrics, and escalation paths so the taxonomy becomes something people can use, not just admire in a slide deck.
What controls work best for AI-specific risks like bias, privacy, and security?
The best controls are layered. For bias and fairness, use dataset reviews, subgroup testing, and human escalation for high-impact decisions. For privacy and data protection, limit sensitive data exposure, enforce retention rules, and test for leakage. For security, add access controls, prompt filtering, red teaming, logging, and incident response for AI systems, especially where external users can interact with models directly.
What should an operating model for AI governance include?
A workable operating model for AI governance spells out who builds, who validates, who approves, who monitors, and who responds when something goes wrong. That usually means product, engineering, security, legal, compliance, and business owners each have defined responsibilities, with clear workflows for intake, risk review, deployment approval, exceptions, and incident handling. If everyone owns AI risk, nobody does.


